学习笔记
前言¶
高级语法与低级语法: 高低级是相对于机器而言的,越高级人越容易阅读理解,越低级机器执行越高效
| Python | C |
|---|---|
| 高级语言 | 非高级语言 |
| 解释性 | 编译性 |
解释性带来的好处就是可以,一行一行执行;编译性需要全部编译成一个可执行文件再执行
基础语法¶
与 C 一些区别:
- python 无需
;分号 - python 不区分单双引号,但前后要匹配
- python 对 缩进/空格敏感
- python 不需要特意声明变量
输入输出¶
python 的输入输出比 C 方便,没有%格式符
输出:print() 已作为 python 的内置函数
输入:input()
PS:input() 输入默认为字符串
类型¶
- int
- float
- bool
- str
可以使用
type()查看类型
运算¶
普通加减乘与 C 一样
对于两个字符串,可以使用+法进行字符串拼接
python 的乘法对于字符串变量有特殊效果
python 的除法有特殊之处:
- 普通除
/,会自动处理精度问题 - 地板除
//,效果等同于 C
还有 & | !
python 可以写成英文字母
三目运算¶
判断¶
:= 是海象运算符
上述 if 条件中不能创建变量 n,使用海象运算符就可以进行创建并赋值
循环¶
while(常用)
for
a = [3,4,5]
# for i in a: # 从 a 拿一个元素赋值给 i
# print(i)
# i
for i in range(len(a)):
print(a[i])
# list(range(1,7))
for i,index in enumerate(a): # i,index 用了拆包语法
print(f"i:{i},index:{index}")
# for 语法也有 break else
a = [1,2,3]
for i in a:
print(i)
# break # break 解释 for 循环
else: # 上面运行完,默认执行一下 else
print("asd")
range(5):产生一个 含有 5 个元素的对象
全局变量与局部变量¶
global
nonlocal
高级/特殊语法¶
函数嵌套定义¶
即 函数里面可以定义函数
拆包语法¶
- python 中
...或pass相当于 c 语言的空语句; - // 地板除
- ** 平方乘
闭包语法¶
def func1():
a = 123
def func2():
print(a)
return func2 # 闭包,返回 func2 函数,等于 c 返回函数指针
b = func1()
b() # 等于运行 func2()
func1()() # 同上
# func1() 里 a 的值会传给 func2(),func2 赋值给 b
# 执行结果
# 123
异常处理¶
- try 异常处理
- try 不能单独存在,必须与 except、else、finally 关键词搭配使用
- python 可以利用 try 异常处理实现 c 语言 goto 语法
- python 有自己一套标准的异常定义,
TypeError、ZeroDivisionError等 菜鸟教程有对这些标准异常的详细介绍 try: #捕获异常 "abc"+123 # TypeError # 1/0 # ZeroDivisionError except: # 异常处理 print("error") # except ZeroDivisionError as e: # 捕获指定异常,并取别名为 e # print(e) # 打印报错的解释 # print("error") # except Exception as e: # 捕获所有异常 # print(e) # 打印报错的解释 # print("error") # # except (ZeroDivisionError, TypeError): # 捕获多个指定异常 # # print("error") # else: # 如果没有捕获到异常 # print("靓仔,谋问题!") finally: # 报不报错最终都会执行,且在报错前执行 print("bye")
除了 try,assert 在 python 中同样适用,assert 判断后面 True/False
匿名函数 lambda¶
用 lambda 定义的函数可以不用取名,适用于只使用一次的场景,取名困难症患者的福音
格式:lambda 参数:返回值
lambda a : a**a
# 等于
def func(a):
return a*a
b = (lambda a : a**a)(2) # lambda a : a**a 就是一个函数
# 等于
b = func(2)
装饰器¶
装饰器本质是闭包,相当于 A 函数被 B 函数包裹,用 B 装饰 A
# 例如,获取某个函数执行时间
import time
def func1(a):
print(a)
time.sleep(1)
t1 = time.time()
func1(1)
t2 = time.time()
t2-t1
# 用装饰器来实现
def get_run_time(fun):
def get_time():
t1 = time.time()
fun()
t2 = time.time()
print(t2-t1)
return get_time
@get_run_time # 装饰器用法,在 func1 外面叠加一个函数
def func1():
print(123)
time.sleep(1)
func1()
迭代器¶
list_iterator
python 的 for 语法里面就有迭代器(in 后面的参数)
# 如要使 a 所有元素+1
a= [1,2,3,4]
for index,i in enumerate(a):
# i = i + 1
a[index]+=1
a
# 上面简单写法
b = [i+1 for i in a]
## 等效于
# b=[]
# for i in a:
# b.append(i+1)
b
## 要取部分内容,可以对 a 切片
# print(a[1:3])
# b = [i+1 for i in a[1:3]]
生成器¶
生成器比迭代器更节省内存
关键字:yield 替代函数里的 return
c = [1,2,3,4]
def func(a):
for i in a: # a 的值赋给 i,后面对 i 操作
yield i+1 # 第一次运行到这返回后,保存资源,第二次继续从这运行,体现“生成”
b = func(c)
next(b)
迭代器应用:斐波那契数列的实现
# 斐波那契数列实现
def fib():
a1,a2 = 0,1
while True:
yield a1
a1,a2 = a2,a1+a2
a = fib()
for index,i in enumerate(a):
print(i)
if index == 10 :
break
a = [1,2,3,4] # [] 列表
(i+1 for i in a) # () 变成生成器
容器¶
字符串¶
标识:" "
python 中 str 类型由容器实现,以 a = "123456789" 为例:
容器的操作:
* 索引,与 C 数组操作一样,支持负数索引
* a[0],取第 0 位数据,输出 1
* a[-1],取倒数第 1 位
* 切片,左包括,右不包括,必须从小到大
* a[2:5],取第 2 到第 4 位的数据,输出 345
* a[-5,-2],取倒数第 5 位到倒数第 3 位,输出 567
* a[:5],取 0 到第 4 位,输出 12345
* a[4:],取第 4 到最后一位,输出 56789
* 使用 len() 获取容器长度,类比 strlen()
列表¶
标识:[ ]
容器的索引切片同样适用
* 索引:取出来是元素
* 切片:切出来还是原来类型
* 赋值:可以直接更改列表里元素的值,a[2] = 9
* + 拼接;* 重复,与字符串一样,不能 -
方法: * append:新增一个元素,如:[1,2,3] 整个放进去 * extend:新增一串元素,如:[1,2,3] 一个一个取出再放进去 * clear:清空 * copy:拷贝 // 区分 c=a 和 c=a.copy() * c=a 相当于指针操作 * c=a.copy() 内存拷贝 * count:计算重复的次数 // 不同 len() * index:从左到右找到元素位置 * insert:插入
del a[0] 删除
a = [1,2,3,4,5,6,7,8]
a.append([1,2,3]) # 1,2,3,4,5,6,7,8,[1,2,3]
a.extend([1,2,3]) # 1,2,3,4,5,6,7,8,1,2,3
a.clear()
c = a # 相当于 a 指针操作,后续对 c 操作同样会影响 a
c = a.copy() # 相当于内存拷贝,c 和 a 各单独一份
a.count(4) # 1, 计算 list 中 4 重复的次数
a.index(4) # 4, 查找第 index 个元素
a.insert(2,[3,3])
a # 1,2,[3,3],3,4,5,6,7,8 在第 2 个位置插入 [3,3]
del a[3] # 删除
元组¶
不能修改的 list 列表,相当于加了 const
标识:可有可无( )
字典 dict¶
标识:{}
{keys:valus}
字典的嵌套使用
集合 set¶
标识:{}
{a,b,c}
特性: 1. 有限性 2. 无序性 3. 唯一性
a = {1,2,3}
b = {4,5,6} # 无序性
a = {1,2,3,3} # 唯一性,可去重
a.add(4)
a.difference(b)
a.discard(1) # 删除
a.intersection(b)
a.union(b) # 并集不会修改原来的 a
A & B # 交集
A | B # 并集
A - B # 差集
A ^ B # 对称差集(在 A 或 B 中,但不会同时出现在 AB 中)
函数¶
def func(arg):- 支持默认参数
arg=1 - 支持指定赋值参数
- 支持返回多个值
return a,b,c - 函数重载
- 可以指定传入参数类型
文件操作¶
f = open("路径/文件名","权限")
权限: | ----- | ----- | ----- | ----- | |:-----:|:----------------:|:-----:|:------------------:| | w | 打开只写文件 | w+ | 打开可读写文件 | | r | 打开只读文件 | r+ | 打开可读写文件 | | a | 追加打开只写文件 | a+ | 追加打开可读写文件 | | -b | 以二进制方式操作 | | |
# 读
f = open("test.txt","w")
f.write("hello world")
f.close()
# 写
f = open("test.txt","r")
txt = f.read()
f.close()
txt
# 追加
f = open("test.txt","a")
f.write("hello world")
f.close()
txt
# 上面的等效替代
# 这种写法无需考虑 close,不用担心没有 close 文件
with open("test.txt","r") as f:
txt = f.read()
print(txt)
with open("hello.txt","w") as d:
d.write(txt)
后一种写法使用更方便,更安全 可以指定以某种编码方式打开文件,如
类与对象¶
对象是类的具象: * 对象是人要进行研究的具体事物 * 对象不仅能表示事物,还能表示抽象的规则、计划、事件 * 对象有属性(状态),我们用变量(value)来描述 * 对象有方法(行为),我们用函数(func)来描述
类是对象的抽象: * 类是具有相同特性和行为的对象的概括、总结 * 类的属性和方法是对对象的状态和行为的抽象
关系: 类的实例化的结果就是对象 对象抽象化的结果就是类
class people:
def __init__(self,name): # class 的构造函数,在 class 创建对象时默认调用
self.name = name
self.food = "没吃"
print(f"创建了{self.name}")
def __del__(self): # 析构函数,在对象删除时调用,用得不多
print("del")
def eat(self, food): # class 里所有 func 第一个参数需要传 self
self.food = food
print(f"{self.name}吃了一个{food}")
def get_eat(self):
print(f"今天吃了{self.food}")
person = people("张三") # 类创建对象的参数默认传给__init__函数
# person.__dir__() # 返回对象所有方法
# person.eat("apple")
person.get_eat()
del person # 使用 del 删除对象
del person.name # 使用 del 删除对象的属性
- 类里面的 func 第一个参数必须传 self,self 参数是对类的当前实例的引用
- 类定义不能为空,可以使用 pass 语句避免错误
库¶
使用库
import os # 普通导入
import os as o # 导入 os 库并重命名为 o
import os.path #导入 os 库里的 path 子模块
from os import path #效果同上,但上面的调用需要 os.path, 这个可以直接 path
- os:系统库
- shutil:os 库补充,专门用来操作文件
- requests:网络相关的
可使用 help() 查看库或函数的帮助文档:help(os.path)
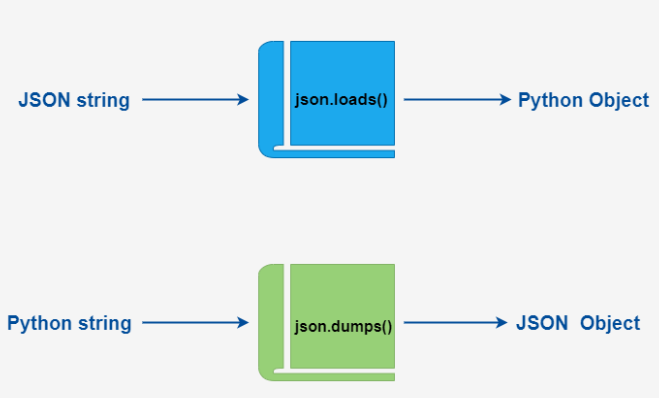
json 库¶
字符串
* json.dumps():编码
* json.loads():解码
python json 类型对应表 编码: | Python | JSON | |:------------:|:------:| | dict | object | | list,tuple | array | | str | string | | int,float... | number | | True | true | | False | false | | None | null | | | | 解码:(不同) | JSON | Python | | ------------- | ------ | | array | list | | number(int) | int | | number(float) | float |
文件
* json.dump():编码
* json.load():解码